YOLOv4理解学习
YOLOv4 理解学习
在经过YOLOv1,YOLOv2,YOLOv3之后,Joseph Redmon金盆洗手,不再更新了,在2020年4月,另一个作者Alexey Bochkovskiy 发布了YOLOv4:YOLOv4: Optimal Speed and Accuracy of Object Detection,得到了Joseph Redmon的认可。
我个人认为该论文写的要比YOLOv1,YOLOv2,和YOLOv3的论文要更加的详实,可以说是非常详细,至少比YOLOv3要详细的多。
首先在
YOLOv4 介绍
YOLOv4在YOLOv3的基础上做了大量改进。加入了许多新的方法,使得这个方法更适合在单GPU上进行训练。YOLOv4主要使用了以下方法
- CutMix 和 Mosaic 数据增强、DropBlock 正则化、类标签平滑
- Mish 激活、跨阶段部分连接 (CSP)、多输入加权残差连接 (MiWRC)
- CIoU-loss、CmBN、DropBlock 正则化、Mosaic 数据增强、自我对抗训练、消除网格敏感性、使用多个Anchoor box处理单个基本事实、余弦退火调度程序 、最优超参数、随机训练形状
- SPP 块、SAM 块、PAN 路径聚合块、DIoU-NMS
YOLOv4 组成
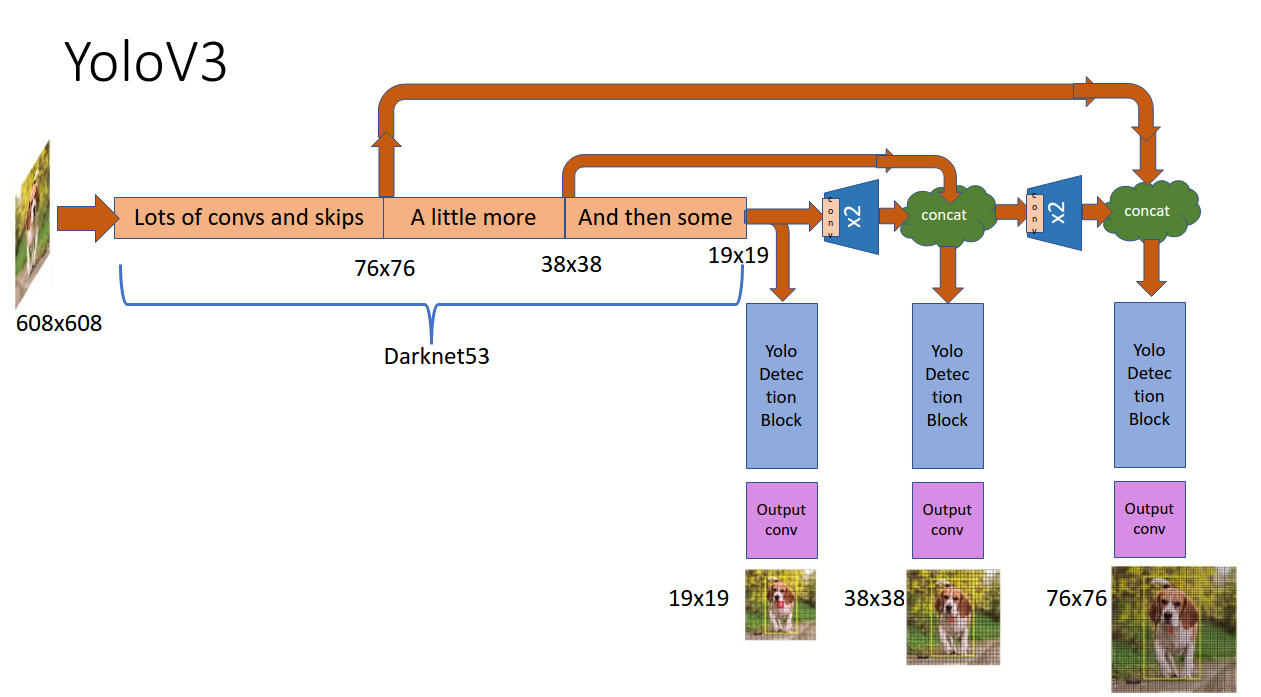
现代检测器通常由两部分组成,一个是在 ImageNet 上预训练的主干(Backbone),另一个是用于预测对象的类别和边界框的头部(Head)。近年来开发的目标检测器通常在主干和头部之间插入一些层,这些层通常用于收集不同阶段的特征图。我们可以称它为物体检测器的颈部(Neck)。如下图所示。
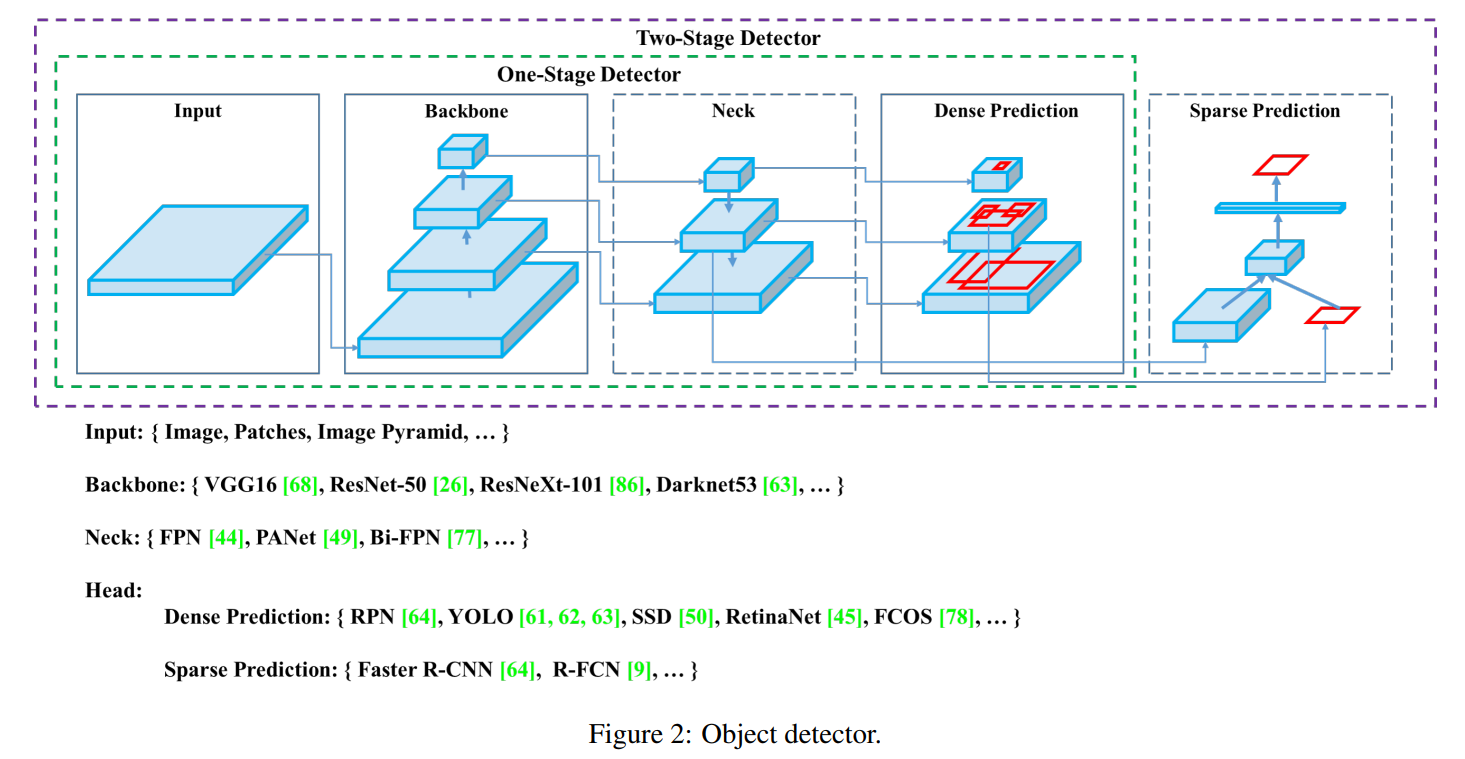
YOLOv4的三部分由以下组成:
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
BoF 与 BoS
BoF
BoF(bag of freebies):使目标检测器在不增加推理成本的情况下获得更好的精度。这类方法一般有以下几种:
- 数据增强
- 解决语言偏差问题
- BBox 回归的目前函数
BoS
BoS(Bag of specials):只增加少量推理成本但能显着提高目标检测准确率的插件模块和后处理方法。有以下几种:
- 扩大感受野
- 加入注意力机制
- 加强特征整合能力
- 更有效的激活函数
基于深度学习的目标检测方法的后处理方法一般使用NMS(非极大值抑制)。
YOLOv4使用
- 用于主干的BoF:CutMix 和马赛克数据增强、DropBlock 正则化、类标签平滑
- 用于主干的 BoS:Mish 激活、跨阶段部分连接 (CSP)、多输入加权残差连接 (MiWRC)
- 检测器的 BoF:CIoU 损失、CmBN、DropBlock 正则化、Mosaic数据增强、自我对抗训练、消除网格敏感性、使用多个Anchor boxes来进行预测、余弦退火调度器,最优超参数,随机训练形状
- 检测器的 BoS:Mish 激活、SPP 块、SAM 块、PAN 路径聚合块、DIoU-NMS
YOLOv4 模型架构
模型架构的选择
两个目标
1、在输入网络分辨率、卷积层数、参数数(滤波器大小2 * 滤波器 * 通道/组)和层输出数(滤波器)之间找到最佳平衡。
2、为不同的检测器级别选择不同的主干级别来增加感受野和参数聚合的最佳方法的附加块:例如FPN、PAN、ASFF、BiFPN
对于模型优化来说,对于分类器的优化方法对于检测器来说并不一定都是优化的,相比于分类器,检测器有以下特点:
- 更高的输入网络尺寸(分辨率)——用于检测多个小尺寸物体、
- 更多层——用于更高的感受野以覆盖更大的输入网络尺寸 、
- 更多参数——用于模型检测多个不同尺寸物体的更大容量单一图像
YOLOv4在 CSPDarknet53 上添加了 SPP 块,因为它显着增加了感受野,分离出最重要的上下文特征并且几乎没有降低网络运行速度。YOLOv4使用 PANet 作为不同检测器级别的不同骨干级别的参数聚合方法,而不是 YOLOv3 中使用的 FPN。最终YOLOv4选择 CSPDarknet53 骨干网、SPP 附加模块、PANet 路径聚合颈部和 YOLOv3(Anchor-based)头作为 YOLOv4 的架构。
架构图
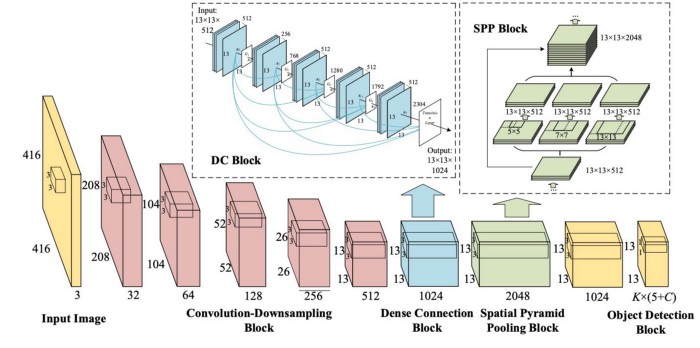
Head
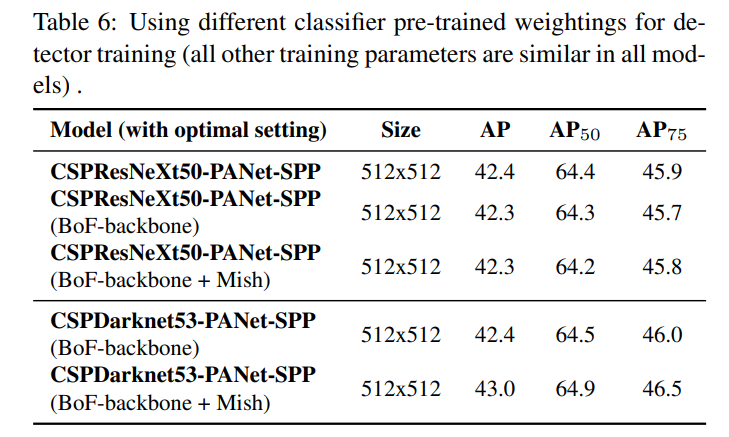
通过更行实验,可以得到以下结论:首先,尽管与 CSPDarknet53 模型相比,用不同特征训练的 CSPResNeXt 50 模型的分类准确率更高,但 CSPDarknet53 模型在对象检测方面表现出更高的准确率。其次,使用 BoF 和 Mish 进行 CSPResNeXt50 分类器训练提高了其分类精度,但进一步应用这些预训练的权重进行检测器训练会降低检测器精度。然而,使用 BoF 和 Mish 进行 CSPDarknet53 分类器训练提高了分类器和使用该分类器预训练权重的检测器的准确性。最终结果是主干 CSPDarknet53 比 CSPResNeXt50 更适合检测器。对比结果如下图所示:
Neck
在 CSPDarkNet53 骨干网和特征聚合器网络 (PANet) 之间添加了一个称为 SPP(空间金字塔池化)的附加块,这样做是为了增加感受野并分离出最重要的上下文特征,并且对网络操作几乎没有影响速度。它连接到 CSPDarkNet 的密集连接卷积层的最后一层。
感受野是指在一个实例中暴露给一个内核或过滤器的图像区域。随着更多的卷积层堆叠,它会线性增加,而当我们堆叠扩张卷积并带来非线性时,它会呈指数增加
堆叠在卷积基础层旁边的 CSP 块,如前所述将输入分成两半,一半将通过密集块发送,而另一半将直接路由到下一步,无需任何处理。 CSP 保留细粒度特征以提高转发效率,刺激网络重用特征并减少网络参数的数量。只有骨干网络中能够提取更丰富语义特征的最终卷积块是密集块,因为更多数量的密集连接的卷积层可能会导致检测速度下降。

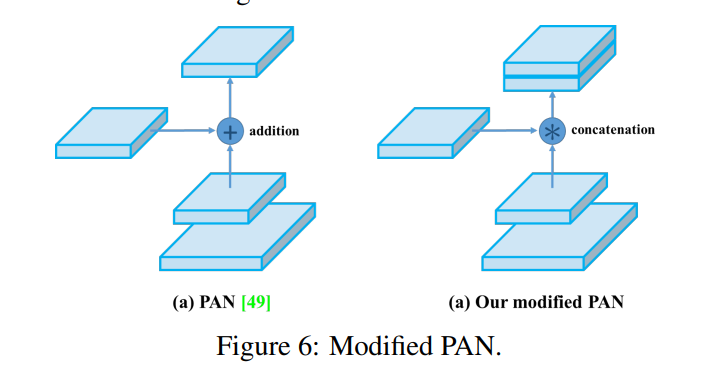
PANet (Path Aggregation Network)
YOLOv4 使用修改后的路径聚合网络,主要作为设计改进,以使其更适合在单个 GPU 上进行训练。
PANet 的主要作用是通过保留空间信息来改进实例分割过程,这反过来有助于正确定位像素以进行掩模预测。自下而上的路径增强、自适应特征池和全连接融合是使它们对掩码预测如此准确的重要属性。
在这里,修改后的 PANet 连接相邻层,而不是在使用自适应特征池(Adaptive Feature Pooling)时添加。
Head
在Head处,YOLOv4和YOLOv3保持一样,也是有3个检测头,分别用于检测不同大小的目标。多尺度预测,小目标,大目标等。请见YOLOv3 理解学习




{kind=link}