
Photoshop自动化处理
前言最近感觉很是空虚,总是做什么事情都做一半,所以在这件事情来了之后,我决定要把它做好,这就是用Photoshop帮助别人做一群带有标号的图片,并且每一张图片上都有一个不同的二维码。
拿到底图
底图是这样子的,如下图,
需要替换的位置是,这张图片上的A001字样和右下角的二维码, 于是我立刻想到了,使用定义变量和导入数据组的方法,做出一个递增数列,将红色文字替换,但是二维码怎么办呢?
使用Adobe acrobat Pro 提取文档中的二维码
发来文档的时候是这样的
   每一页有十张二维码,一共329页,当时我在想,我是谁,我在哪,这是什么。。。。
但是我没有放弃,这点东西绝对不能阻止我
打开某度,开始搜索acrobat如何导出图片,在费尽千辛万苦之后终于找到了导出文档中的图片,而不是将pdf做成图片的方法,
点击二维码上面的此为图片,然后acrobat就会认识这种类型的图片。然后使用acrobat的工具中的导出所有图片。
导出后命名格式是这样的
这样看起来很乱,分不清哪张是哪张,然后接下来 ...

服务器软件使用说明(学生端)
服务器软件使用说明 学生版本文以笔者所在学校东北大学秦皇岛分校(以下简称NEUQ)服务器设置为基础,说明了服务器的通用使用方式,其中只涉及软件部分,即硬件准备就绪的情况,包括但不限于电源,网卡,显示器、键盘等外部设备。
新购置的服务器通常预装了单一系统。在科研领域,特别是深度学习方面,Ubuntu系统因其免费、稳定性高和强大的社区支持而广受青睐。众多科研人员选择Ubuntu,使得其使用基数庞大,因此遇到的各种问题及其解决方案也十分丰富。对于初学者而言,这意味着他们可以从互联网社区中获取到大量的经验和帮助。
本文所有的设置与软件安装,基于Ubuntu 20.04 LTS版本。LTS是Long Term Support的缩写,意味着长期支持,因此系统通常较为稳定。一个稳定的操作系统对于实验环境至关重要,它是确保稳定进行实验研究的先决条件,为科研活动的顺利进行提供了必要的保障。
对于操作系统来说,我个人建议是不要安装图形界面,因为有些图形界面系统会导致一些系统中断。但另一方面,图形界面会让人有一个直观的感受,因此本文会介绍部分图形界面相关的内容。另外,对于计算机视觉方面的程序会有一些必须需要 ...
YOLOv5理解学习
YOLOv5 理解学习
YOLOv5还没有论文出现,只公布了源码,本篇是翻译的YOLOv5 github仓库中的Issue
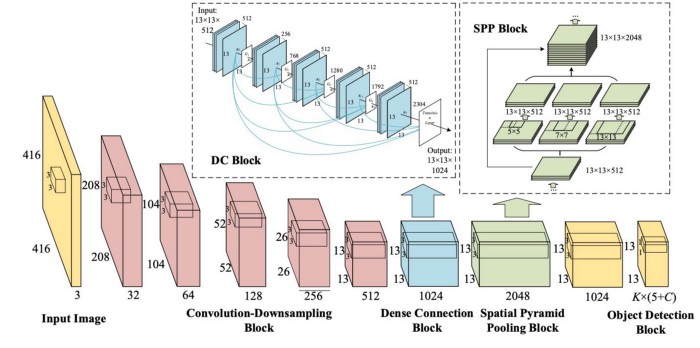
YOLOv5 模型架构YOLOv5组成YOLOv5(v6.0/6.1)和普通的目标检测器相类似,由三个部分组成,分别为Backbone,Neck,Head,它们分别为
Backbone:New CSP-Darnet53
Neck:SPPF,New CSP-PAN
Head:YOLOv3 Head
YOLOv5架构图
YOLOv5 v6.0 与 YOLOv5 之前的版本,相比有一些小的变化
将 Focus 结构替换成为 $6\times6$ Conv (这个在 Issue 4825问题中有详细说明,是由开发者向ultralytics提出的验证,作者验证通过之后,便更新了这一点,不得不感叹社区的和谐 )
12345678910class Focus(nn.Module): # Focus wh information into c-space def __init__(self, c1, c2, k=1, s=1, p=None, g=1 ...
YOLOv4理解学习
YOLOv4 理解学习在经过YOLOv1,YOLOv2,YOLOv3之后,Joseph Redmon金盆洗手,不再更新了,在2020年4月,另一个作者Alexey Bochkovskiy 发布了YOLOv4:YOLOv4: Optimal Speed and Accuracy of Object Detection,得到了Joseph Redmon的认可。
我个人认为该论文写的要比YOLOv1,YOLOv2,和YOLOv3的论文要更加的详实,可以说是非常详细,至少比YOLOv3要详细的多。
首先在
YOLOv4 介绍YOLOv4在YOLOv3的基础上做了大量改进。加入了许多新的方法,使得这个方法更适合在单GPU上进行训练。YOLOv4主要使用了以下方法
CutMix 和 Mosaic 数据增强、DropBlock 正则化、类标签平滑
Mish 激活、跨阶段部分连接 (CSP)、多输入加权残差连接 (MiWRC)
CIoU-loss、CmBN、DropBlock 正则化、Mosaic 数据增强、自我对抗训练、消除网格敏感性、使用多个Anchoor box处理单个基本事实、余弦退火调度程 ...
Windows下利用excel完成批量命名
Windows下完成对应批量命名背景介绍在工作和学习过程中,常常需要用到重命名操作,命名内容在excel文件中,手动为每个文件进行命名费时费力,还非常容易出错,此时我们可以使用Windows下的批处理方法来进行重命名。下面是一个简单的案例。
首先我们有一个原始的Excel 文件
还有下面的这样一些文件
需要做的工作就是将这些文件由学号.txt一一对应的命名成姓名.txt
构建Windows Bat脚本在Excel中构建对应的文件名首先打开存着学号和姓名的excel文件
删除表头,并使用CONCAT函数将学号列和姓名列都加上文件的后缀名.txt(也可以是其它),得到下面这个样子
同理得到将命名的列,如下
CONCAT函数的作用:将所有输入的参数连接起来,可以查看CONCAT 函数 - Microsoft 支持
在前面加上一个ren 或者rename,如下:
ren的作用就是将后面两个文件名中的第一个重命名为第二个,可以查看ren | Microsoft Learn
将ren和随后的两列,共三列选中复制到一个记事本文件中。
制作脚本将这个文件的文件扩展名改为.bat, ...

在夜晚中的一点点小想法
关于自己的一点点想法今天晚上在学校操场快速走路,走着走着我竟然跑了起来,仿佛是在逃避着什么,耳机播放着几年前唱的歌,歌声显得如此熟悉,却不如现在动听,随着自己的进步,对原来的批评和建议惭惭理解,但是却依然对这声音感到十分亲切,这是我进步的过程,但是听我歌声的人却越来越少了。
由此联想到,曾经弱小变到现在,很少有人看到原来的差劲,仿佛这能力与生俱来。即使是遇到,也只是一笑而过,短暂的钦佩,从头到尾都只有自己,愿意从始陪着自己慢慢前进,自己接受着自己,从平庸到变强,或者一直平庸,不管如何,不管什么发生,这大抵也许就是正常的生活。
但是我们却经常忘了自己,心里装着的人或事儿,大多是束缚,有时候做自己一下,枷锁却又变得更紧。 听着我从前的歌声,好想抱抱原来固执的自己,孤独的自己,曾经的自己想必一定是渴望有个人愿意陪着自己,尽管原来的歌声有些难听,有些稚嫩,但却是我最亲切的声音。
有时候有人会说,你做的这些自我感动的事情,毫无意义,其实不然,这有意义;每当说没有意义的时候,只是对言者没有意义或者是拖累。但对于行者而言,此绝非无用,这是能做的最好的事情,感动自己的事儿往往倾注了自己的全部 ...
YOLOv3理解学习
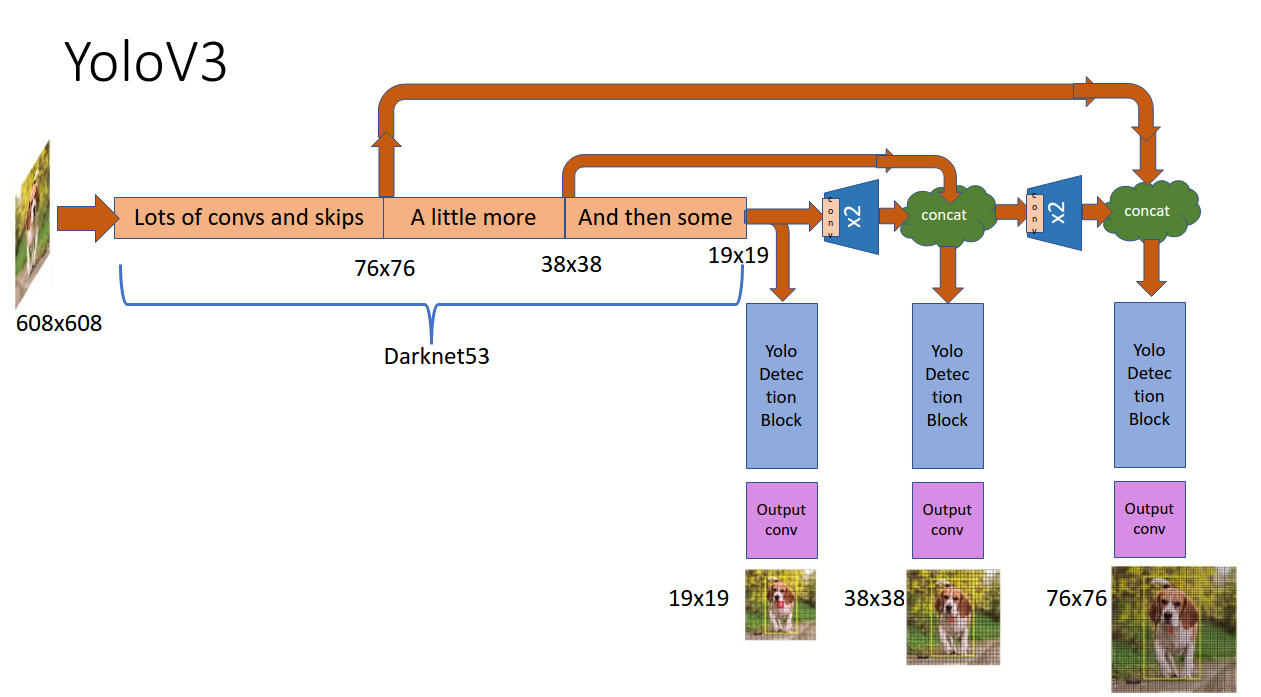
YOLOv3 理解学习经过YOLOv1,YOLOv2(YOLO9000)之后,Joseph Redmon 迎来了他的又一新作 YOLOv3: An Incremental Improvement,YOLOv3这不是一篇正常的论文,只是一个工作报告。比较晦涩难懂。
YOLOv3 特点
YOLOv3保持了和前面的YOLOv1,YOLOv2一样的优点,就是快,另外在性能上提升了不少,精确度和SSD一样,但是速度却是SSD的三倍。
YOLOv3的锚框(Anchor Box)使用了3个锚框,依旧是采用聚类算法进行锚框的选择。
模型的网络结构更加的复杂采用的是Darknet-53
YOLOv3加入了多尺度预测的方法。
YOLOv3锚框的变化YOLOv3对预测框的偏移量是保持原来不变,和YOLOv2一样的,如下所示:
bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_we^{t_w} ...

YOLOv2理解学习
YoloV2 理解学习接替YOLO,YOLO的作者Joseph Redmon又改进了YOLO,做出了YOLO9000,也就是平常我们所说的YOLOv2;它的论文是YOLO9000: Better, Faster, Stronger 。发表在CVPR2017。
YOLOv2简介YOLOv2的原始论文叫做YOLO9000,YOLO9000的来历是,在2017年前,与其它任务相比,目标检测的数据集是非常少的,作者想到一种方法,将ImageNet中的分类数据集与目标检测的MSCOCO数据集一块儿训练,因为ImageNet中的数据集种类非常多,有几千种,将这两种数据集结合在一起训练则会有9000多种类别。因此YOLO9000就出现了,但是一块儿训练的效果有限。
YOLOv2特点由题目可以看出,YOLOv2有三大优点:分别是 Better,Faster,Stronger,我们分别对其进行介绍,因为Stronger不是目标检测方面的提升,因此暂时不讨论这个方面。
BetterYOLO与R-CNN相比,有更多的定位错误(Localization Errors),且目标都检测出的能力较低(Recall ...
pycharm & brower revoke remote resources
pycharm & 浏览器使用远程jupyter & 资源视频演示

YOLOV1的学习
Yolov1 的学习最近在看Yolov5,但总感觉是丈二和尚摸不着头脑,于是就想着把所有的Yolo整个系列看一下,顺便了解一下整个计算机视觉目标检测方面的内容
Yolo v1的简介YOLO V1 (以下称为YOLO) 的论文是 You Only Look Once: Unified, Real-Time Object Detection ,这一篇论文发表在CVPR上面,CVPR 也是计算机视觉与模式识别的顶级会议。
YOLO 在当时首次出现就表现出了又快又准确的特点,简单来说就是:比我好的没我快,比我快的没我好。当时它快到一秒可以检测45张图片,也就是达到了 45FPS,即,实时检测。
与当时比较强的R-CNN类的框架相比,YoloV1是一个完成的一趟下来的框架,因此它没有中间繁琐的流程,一次搞定,这也就是它为什么快的原因。
YOLO 特点YOLO is refreshingly simple: Yolo的识别如下图所示
YOLO 是一个联合的完整的模型,有以下优点:
它非常快,因为它把图像预测作为一个回归问题来进行,就是说将图片的像素当成数字,直接输出一串概率向量。
它看整张图片 ...