YOLOv3理解学习
YOLOv3 理解学习
经过YOLOv1,YOLOv2(YOLO9000)之后,Joseph Redmon 迎来了他的又一新作 YOLOv3: An Incremental Improvement,YOLOv3这不是一篇正常的论文,只是一个工作报告。比较晦涩难懂。
YOLOv3 特点
YOLOv3保持了和前面的YOLOv1,YOLOv2一样的优点,就是快,另外在性能上提升了不少,精确度和SSD一样,但是速度却是SSD的三倍。
YOLOv3的锚框(Anchor Box)使用了3个锚框,依旧是采用聚类算法进行锚框的选择。
模型的网络结构更加的复杂采用的是Darknet-53
YOLOv3加入了多尺度预测的方法。
YOLOv3锚框的变化
YOLOv3对预测框的偏移量是保持原来不变,和YOLOv2一样的,如下所示:
但是这次采用3个Anchor Box,YOLOv3采用逻辑回归来预测每个边界框的objectness score(可以叫作置信度分数,和YOLOv1中的confidence score是相同的,就是当前框含有目标的概率)。如果3个Anchor Box中的其中一个覆盖的groundtruth比其余的大于一个阈值,则会将这个框的权重设置为1,其余的设置为0,忽略另外两个。在YOLOv3中的穿上阈值设置为0.5。
YOLOv3类别预测
YOLOv3中的预测因为一个bounding box可能会包含一个多标签的类别。在YOLOv3中不使用softmax分类器,而是使用一个逻辑回归分类器,这两个的效果一样,但是逻辑回归的分类器会对多标签类别有一个良好的策略。(多标签:如人和女人,其中一个类别包含另一个类别等重合的类别)。
YOLOv3多尺度预测
YOLOv3有3个尺度的预测,YOLOv3采用了FPN(feature pyramid networks)来进行多尺度的特征提取。在Anchor Box的选择上依然使用k-means 聚类算法进行选择,使用9个聚类随机算出3个尺度的Anchor Boxes。
FPN论文:Feature Pyramid Networks for Object Detection
YOLOv3特征提取器
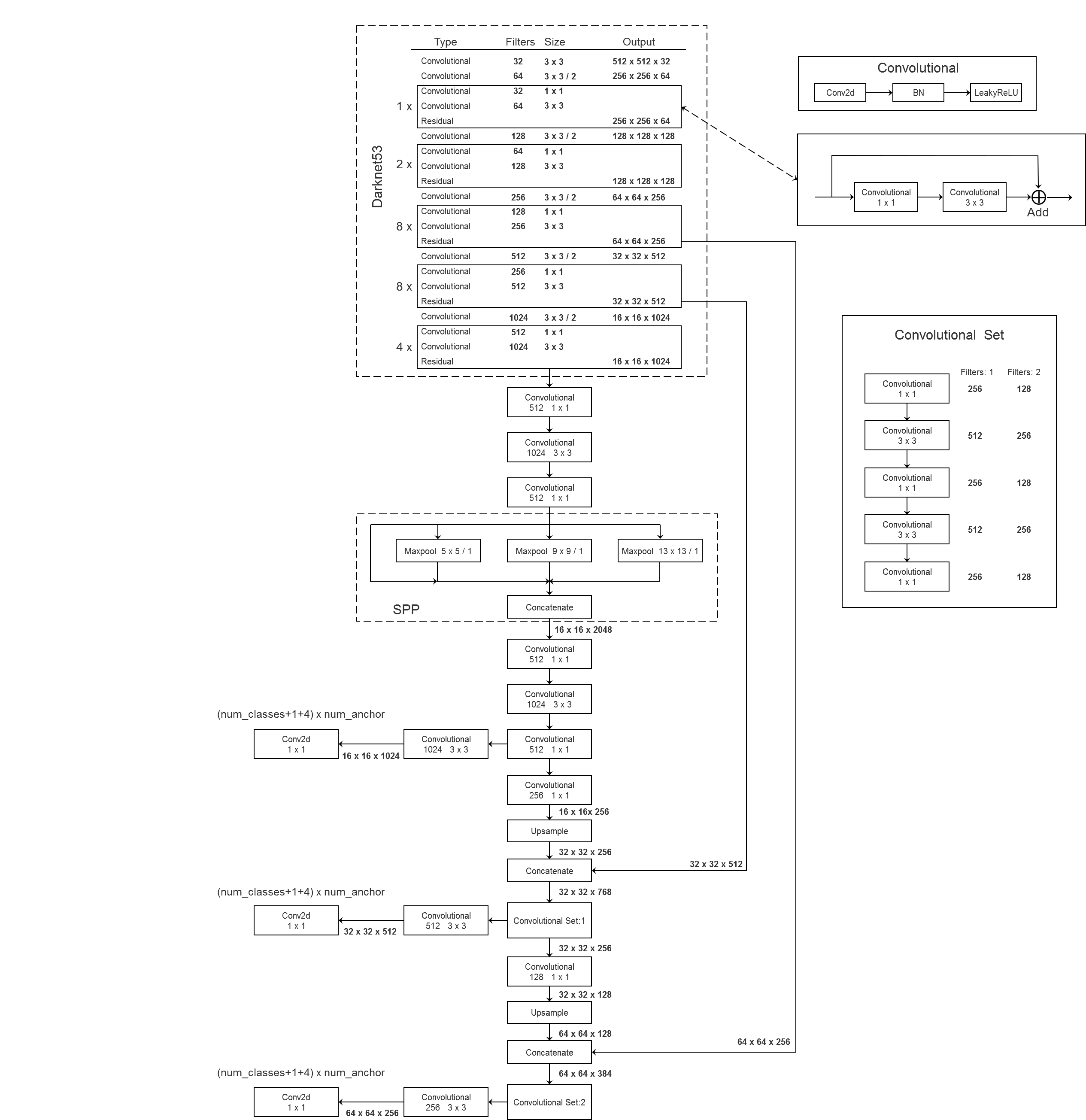
YOLOv3采用了Darknet-53来作特征提取网络,如下图所示
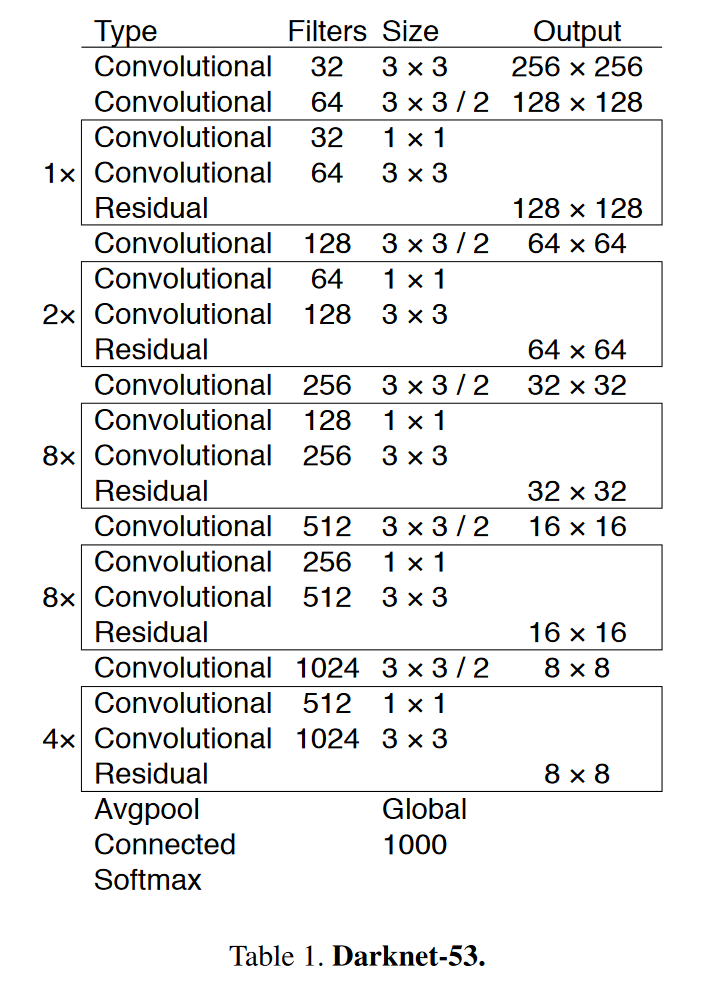
Darknet 53和采用了一种合并的方法,将Darknet19和Residual残差结构放在一块儿。使用了一些连续的$3\times3$和$1\times1$卷积层来进行,期间还有一些残差网络。这个网络比Darknet19强大太多了,达到了和ResNet101与ResNet152相差无几的精度,下图是一些比较:
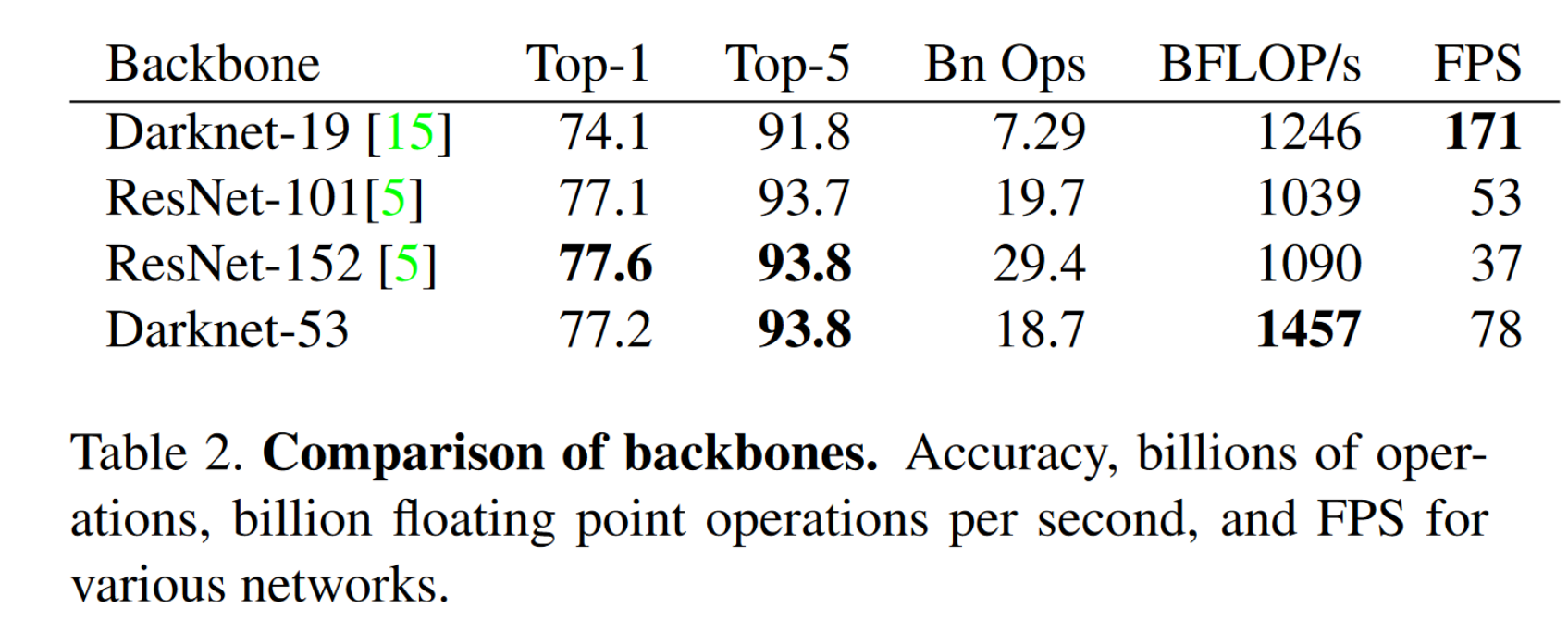
可以看出,Darknet53和ResNet-101和ResNet-152的效果是相差无几的,但是速度上,Darknet53要比其余两者要好的多。而且BFLOP/s (Billion Float operations per second) Darknet网络是比较高的,意味着Darknet有更好的GPU利用率。很有可能是因为ResNet有更多的层,101,152,因此效率上可能不是那么强。
细节
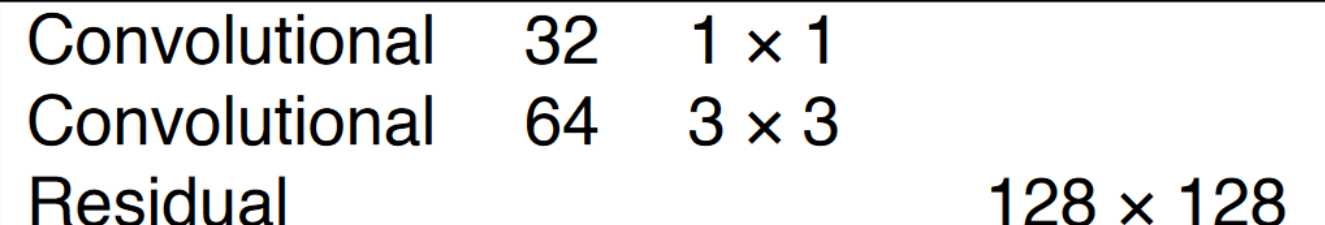
这个Block 借鉴了 ResNet中的残差网络,
下图为ResNet的一个Block
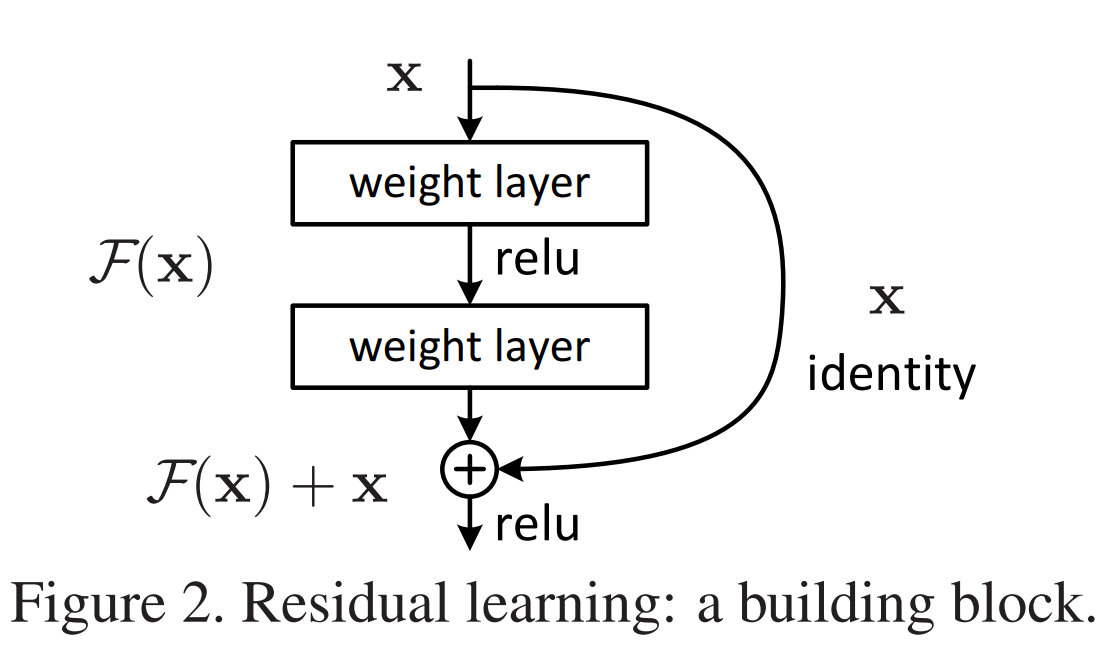
ResNet原文:Deep Residual Learning for Image Recognition
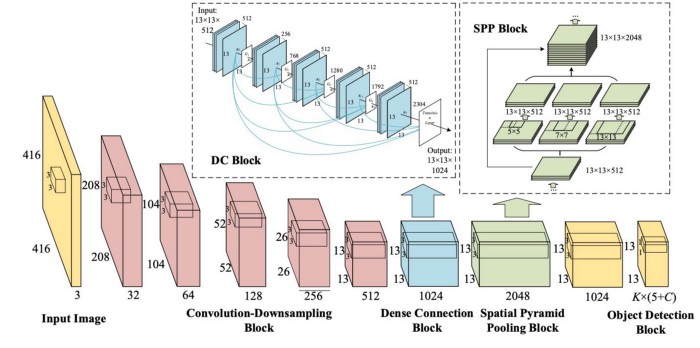
YOLOv3的网络架构
下面是YOLOv3比较详细的一个图
简略图
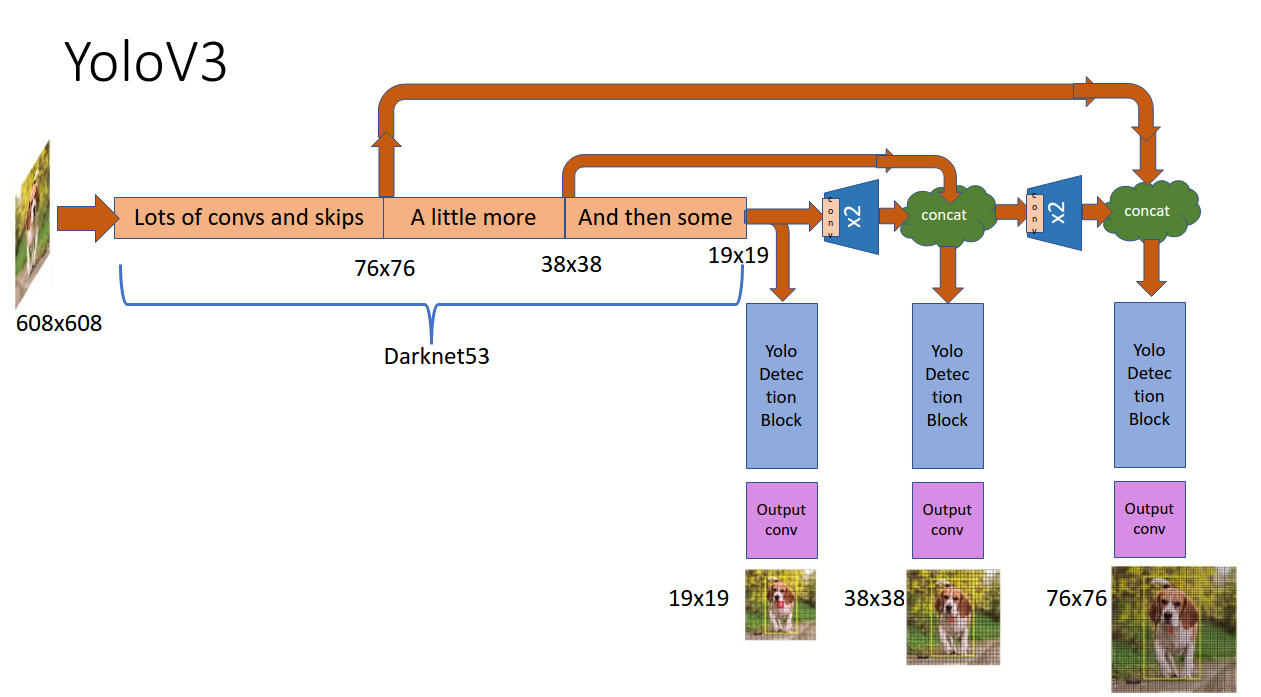
可以看到,先通过Convolutional卷积层进行下采用,而不是Pooling,另外将提取后的特征更行上采样,与原来下采样得到的数据来进行一个连接,可以得到更多的语义信息,来预测中目标和大目标。
YOLOv3的损失函数
参考
YOLOv3 架构图转载自 https://github.com/WZMIAOMIAO/deep-learning-for-image-processing