YOLOV1的学习
Yolov1 的学习
最近在看Yolov5,但总感觉是丈二和尚摸不着头脑,于是就想着把所有的Yolo整个系列看一下,顺便了解一下整个计算机视觉目标检测方面的内容
Yolo v1的简介
YOLO V1 (以下称为YOLO) 的论文是 You Only Look Once: Unified, Real-Time Object Detection ,这一篇论文发表在CVPR上面,CVPR 也是计算机视觉与模式识别的顶级会议。
YOLO 在当时首次出现就表现出了又快又准确的特点,简单来说就是:比我好的没我快,比我快的没我好。当时它快到一秒可以检测45张图片,也就是达到了 45FPS,即,实时检测。
与当时比较强的R-CNN类的框架相比,YoloV1是一个完成的一趟下来的框架,因此它没有中间繁琐的流程,一次搞定,这也就是它为什么快的原因。
YOLO 特点
YOLO is refreshingly simple: Yolo的识别如下图所示

YOLO 是一个联合的完整的模型,有以下优点:
- 它非常快,因为它把图像预测作为一个回归问题来进行,就是说将图片的像素当成数字,直接输出一串概率向量。
- 它看整张图片,不像R-CNN,R-CNN使用的是一种滑动窗口的方式进行的,只能看到图片的一部分而不能看全局的内容,所以相对于R-CNN来说,YOLO会有更小的背景误差,即,它不会将背景识别成为一个物体。
- 它有更好的泛化能力,在自然事物的图片上进行训练,在艺术作品上进行测试,mAP也不会降低的很小。
虽然YOLO当时表现的不是最好的,但是它却比较快。即,比它好的没它快,比它快的没它好。
YOLO统一检测
YOLO将原来所有的目标检测组件组合在一个简单的神经网络中。这个网络用整张图像的Feature来进行bounding boxes的预测,同时也预测出了所有类别的bounding boxes。YOLO的设计上就可以进行end-to-end的检测。
检测的步骤说明
输入一张图片,将这张图片分为 $S \times S$个grid cell
每一个grid cell会预测出$B$个待定的bounding boxes 和 对应的 confidence score,
- 其中每个confidence score就是bounding box 中含有目标的概率$Pr(Object)$和 这个bounding box与 ground truth 的IOU的乘积。bounding box 的中心点需要落在grid cell中。
- 如果没有目标在这个bounding box中,则confidece score 就会趋向于0。
- 每一个bounding box 由五个预测值 $(x, y, w, h, c)$。其中$(x, y)$是bounding box 的中心点的位置。$(w,h)$ 是bounding box的宽度和高度。$c$ 为confidence score。
每个grid cell 还会预测出 $C$ 个分类的条件概率即 bouding box中含有目标的条件下,是这个目标的概率,用公式来表示就是 $ Pr(Class_i | Object) $。
经过网络之后最后输出的向量为 $(S, S, (B \times 5 + C))$,其中$S \times S$为grid cell 的个数,$B \times 5$ 表示每个bounding box的$5$个预测值 $(x, y, w, h, c)$,$C$ 表示$C$个类别的条件概率。
后面进行一下计算,将条件概率和 bounding box 的 $Pr(Object)$相乘,得到最终的概率
经过一个NMS,得到最终的预测值
NMS
可以通过下图理解什么是 YOLO中的NMS
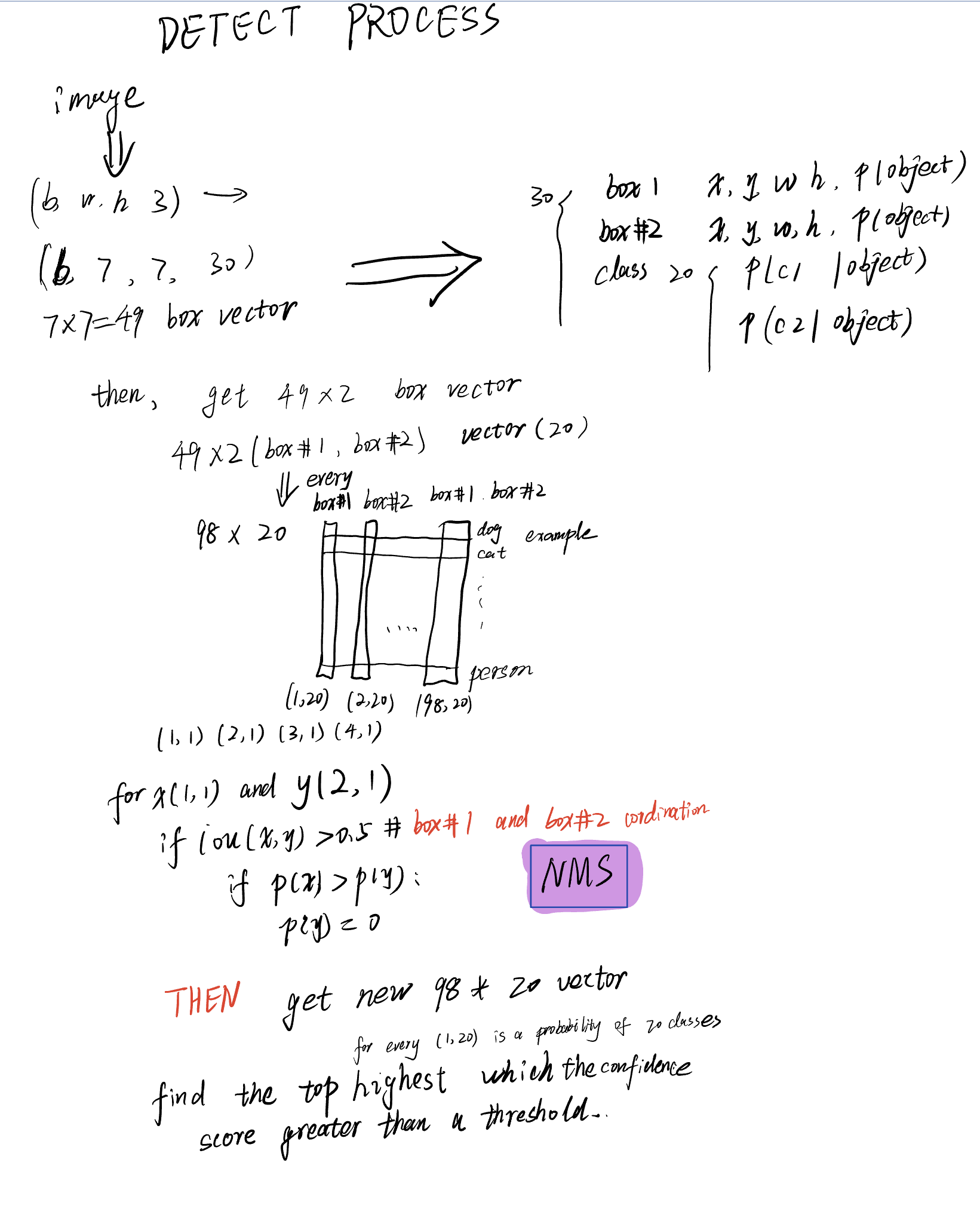
在 YOLO 于 PASCAL VOC 数据集上,$S=7,B=2.C=20$
对于这个检测步骤,需要结合下面的架构来进行加深理解
YOLO 的架构
下面是YOLO的架构

YOLO采用了24个卷积层和两个全连接层。在ImageNet上的$224 \times 224$的图像上进行训练,在$448 \times 448$的图像上进行检测。还训练了一个Fast YOLO 使用了 9 个卷积层,替换了YOLO的24个卷积层
最后一层预测出了bounding box的坐标和类别的概率,将bounding box 的长和宽进行标准化,使它们都落在 $0 ~ 1$ 之间,同样的对于每个bounding box来说他们的长和宽相对于grid cell的偏移量也是在 $0 ~ 1$ 之间。
最后一层使用了一个线性的激活函数,其他层使用了leaky 这个激活函数。
损失函数为
这里的损失计算方法使用的是 SSE(Sum-Squared Error),因为这样求一次导就可以变成一次项,第二部分使用的是对 w 和 h 取根号,是要弱化小框产生的差异。(SSE反映了小框在大框中产生的问题会小于小框在小框中的差异,使用这种方法可以弱化)
上述Loss,对有目标的部分做了一个提升的权重,对没目标的部分做了一个减弱权重分别为 $ \lambda_{ coord } = 5,\lambda_{ noobj }=0.5 $
YOLO 干预
YOLO 非常快,因为它将所有过程都放在一个简单的网络中进行评估。可以达到45FPS,达到实时的检测,不像其他的R-CNN 和 DPM,加上NMS可以让YOLO提升 2~3%的mAP。
YOLO的局限性
因为YOLO强制每个grid cell 只能预测一种类别的物体,因此当物体非常密集的时候,YOLO的预测就没有太高的准确率了,如鸟群等密集型的图片。
YOLO使用的是粗粒度的预测,因为YOLO的架构中有许多下采样的层。
Loss 把小框和大框的损失计算相对均衡,但是一个小的error在大框中是良性的,但是对于一个小框来说的话,一个小的错误就失之毫厘,差之千里了,因此YOLO的定位能力有限(仅限于YOLO的v1版本)
英文说明
- mAP:mean Average Precision, 即各类别AP的平均值,计算方法为PR曲线(Precision-Recall曲线)下的面积
- FPS:每秒传输帧数(Frames Per Second),即1秒可以处理多少张图片
- feature: 特征,使用卷积核来提取图像特征
- bounding box: 最小包围框,一般是用做目标检测中预测框
- IOU: Intersection over Union,bounding box 和 ground truth框的相交部分 / 二者的并的部分
- grid cell: 网格,把图片平均分为S * S块,每一块就是一个 grid cell
- confidence score: 置信度分数
- NMS: 非极大抑制,如果不是极值,就对其进行抑制,在YOLO中,抑制为0